Flagship · Case study
JustAi & an observability layer for fleets of engineering agents.
JustAi is public now: the project at github.com/JustinJLeopard/JustAi and the canonical visitor path is /demo/justai. It is a multi-agent orchestration demo instrumented end-to-end: intent → plan → execute → review → synthesize. Cost, latency, trajectories, and learnings surfaced as first-class data so operators can reason about routing, escalation, and review quality from evidence instead of vibes.
The problem with multi-agent teams
Single-agent tools make every decision look deliberate. Put five agents on one project and the opposite happens: cost blooms, trajectories diverge, and nobody can tell whether the fleet is learning or just repeating the same expensive mistakes with confidence.
JustAi was built to answer a tighter question: can we treat an agent fleet like an operational system — with SLOs, traces, and a review gate — and have operators ship more software, cheaper, than a comparable human team with an IDE?
Architecture, in one paragraph
A coordination plane (SpacetimeDB) holds the task queue, agent roster, and run state as one reactive source of truth. LiteLLM fronts every model provider so routing is a config change rather than a code change. Tracing captures cost, latency, and quality. A claude-flow-compatible MCP server exposes project tools to whichever agent claims the task. A review agent gates "done" on real assertions instead of vibes. Trajectories — every command, every escalation — are persisted for post-mortem analysis and for training the next routing decision. JustAi sits above the public *-mini family: safe-mini for safety, lab-mini for data-science labbing, route-mini for multi-provider LLM routing with fallback, and memory-mini for durable agent memory.
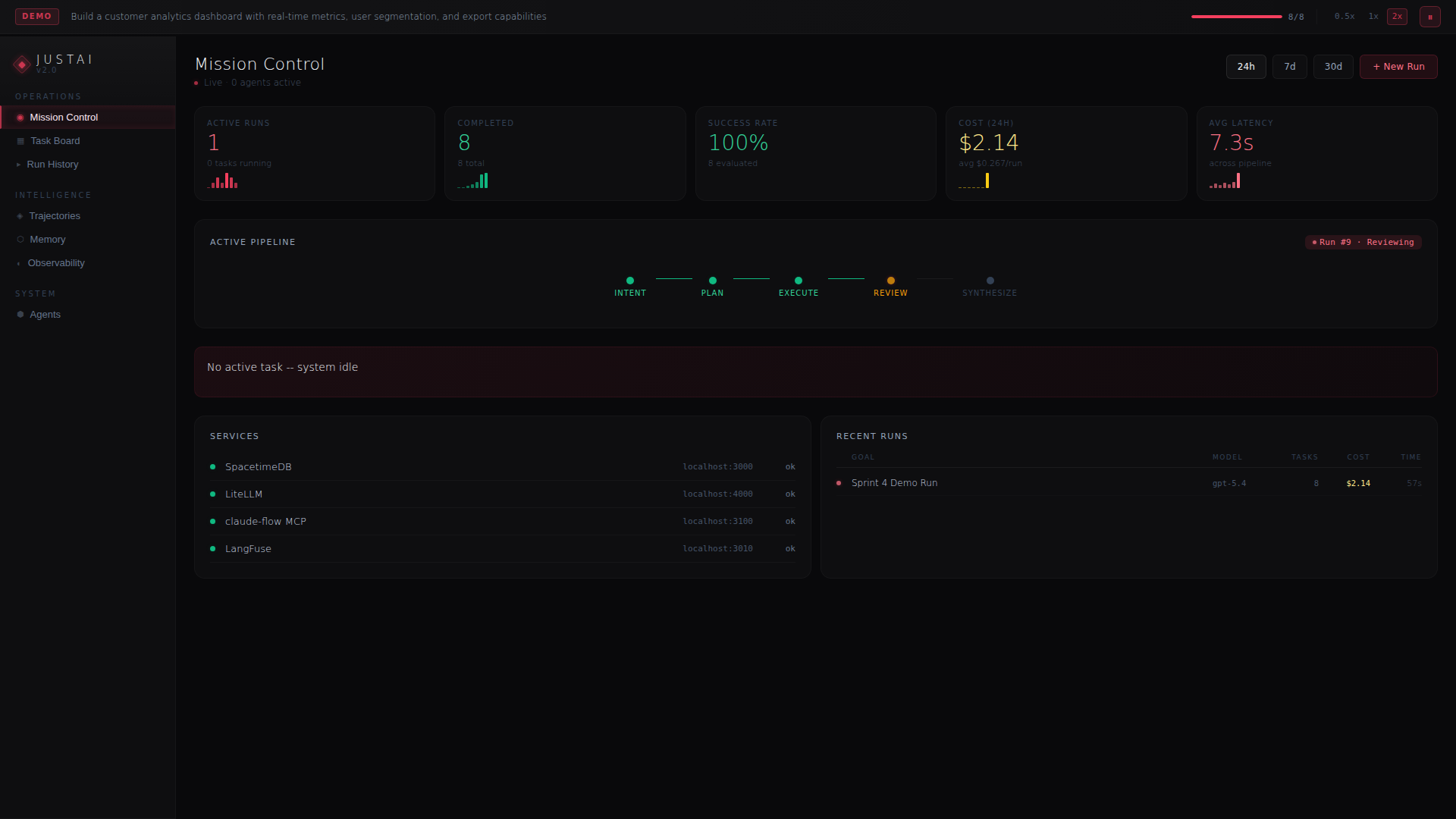
What's on screen
Six dashboards make the pipeline legible. Read them left-to-right, in the order below — this is the same path an operator walks through when a run lands on their desk.
Walkthrough · six dashboards
The fleet, on one pane of glass.
Click any frame to open the larger view. Arrow keys navigate; Esc closes.
Routing as policy
Early on, the planner escalated to the strongest available model for any task it didn't immediately understand. The observability dashboard made the cost of that habit impossible to ignore: not every uncertain task deserves the most expensive planner, especially when prior trajectories show a cheaper executor has already solved the same shape of problem.
Routing is now a policy derived from trajectory history: a cheaper executor for implementation and a stronger planner only when task risk, provider health, or prior failure history justifies it. Tier escalation is policy, not magic — see Parallel Sessions, Shared Substrate for the operational story. The policy is expressed as a typed memory record, so agents can retrieve it, argue with it, and update it when a run proves it wrong.
Trajectories as training data
A trajectory is the full command replay of a run — tool calls, errors, recoveries, the exact point where an agent gave up and asked for help. JustAi persists trajectories as structured data alongside a machine-written post-mortem. New runs retrieve relevant trajectories as context, so the fleet's failure modes compound forward instead of repeating.
This is where the observability layer stops being a dashboard and starts being infrastructure. A fleet without trajectory memory re-learns the same lesson every sprint. A fleet with it gets cheaper and more honest as it runs.
The six-stage pipeline, concretely
Intent parses the operator's goal into a typed task spec — surface area, acceptance criteria, budget envelope, allowed escalation ceiling. Plan decomposes the task into a sequence of sub-tasks, each tagged with the shape of agent that should claim it. Execute is the open stage: whichever agent takes the work runs it through LiteLLM, uses the MCP-exposed project tools, and writes results back into the coordination plane. Review runs a separate model against the diff and the acceptance criteria — not a rubber stamp, a second opinion that gates merge. Synthesize compacts the run into a durable artifact: diff, trace, cost breakdown, decision record. Report surfaces all of it to the operator with the exact information needed to approve, escalate, or retry.
Each stage is instrumented. Each stage has a time budget, a cost ceiling, and a quality gate. When one trips, the pipeline surfaces the specific stage and the specific dashboard that diagnoses it — which is why the six screens above map one-to-one to the six ways a run can go sideways.
The evaluation loop
The review agent closes the loop, but the loop would be a waste of tokens without a signal that's richer than pass/fail. Every review writes a structured verdict: what it checked, which assertions held, which drifted, and what the cheapest remedy looks like. Those verdicts flow into the memory store as typed entries, which the planner queries on the next related task.
The upshot is a learning signal that survives restarts and onboarding. A new operator should not have to rediscover the same model/tooling mismatch that a prior run already exposed; the planner should retrieve that evidence before it routes. Evaluation becomes the substrate the routing policy stands on, rather than a lagging report that nobody reads on a Friday.
What I'm watching next
- Cost-aware planners. The planner currently optimizes for success; the next iteration optimizes for success-per-dollar against a budget envelope set at the run level.
- Memory decay. Typed memory entries need a half-life. A pattern that was true six months ago on React 18 may be actively harmful on React 19. Decay plus confidence-weighted retrieval rather than infinite context.
- Human-in-the-loop, without the friction. A review UI that lets the operator approve a direction without context-switching out of the run. The bottleneck is almost never the model — it's the shape of the human's interface to it.